
 with lower memory and compute costs.){kind=link}
Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Enterprises increasingly rely on large language models (LLMs) to deliver advanced services, but struggle to handle the computational costs of running models. A new framework, chain-of-experts (CoE), aims to make LLMs more resource-efficient while increasing their accuracy on reasoning tasks.
The CoE framework addresses the limitations of earlier approaches by activating “experts” — separated elements of a model, each specializing in certain tasks — sequentially instead of in parallel. This structure allows experts to communicate intermediate results and gradually build on each others’ work.
Architectures such as CoE can become very useful in inference-intensive applications, where gains in efficiency can result in huge cost savings and better user experience.
Dense LLMs and mixture-of-experts
Classic LLMs, sometimes referred to as dense models, activate every parameter simultaneously during inference, leading to extensive computational demands as a model grows larger. Mixture-of-experts (MoE), an architecture used in models such as DeepSeek-V3 and (assumedly) GPT-4o, addresses this challenge by splitting the model into a set of experts.
During inference, MoE models use a router that selects a subset of experts for each input. MoEs significantly reduce the computational overhead of running LLMs compared to dense models. For example, DeepSeek-V3 is a 671-billion-parameter model with 257 experts, nine of which are used for any given input token, totaling 37 billion active parameters during inference.
But MoEs have limitations. The two main drawbacks are, first, that each expert operates independently of others, reducing the model’s performance on tasks that require contextual awareness and coordination among experts. And second, the MoE architecture causes high sparsity, resulting in a model with high memory requirements, even though a small subset is used at any given time.
Chain-of-experts
The chain-of-experts framework addresses the limitations of MoEs by activating experts sequentially instead of in parallel. This structure allows experts to communicate intermediate results and gradually build on each others’ work.
CoE uses an iterative process. The input is first routed to a set of experts, which process it and pass on their answers to another set of experts. The second group of experts processes the intermediate results and can pass them on to the next set of experts. This sequential approach provides context-aware inputs, significantly enhancing the model’s ability to handle complex reasoning tasks.
For example, in mathematical reasoning or logical inference, CoE allows each expert to build on previous insights, improving accuracy and task performance. This method also optimizes resource use by minimizing redundant computations common in parallel-only expert deployments, addressing enterprise demands for cost-efficient and high-performing AI solutions.
Key advantages of CoE
The chain-of-experts approach, using sequential activation and expert collaboration, results in several key benefits, as described in a recent analysis from a group of researchers testing the CoE framework.
In CoE, the expert selection is performed in an iterative fashion. In each iteration, the experts are determined by the output of the previous stage. This enables different experts to communicate and form interdependencies to create a more dynamic routing mechanism.
“In this way, CoE can significantly improve model performance while maintaining computational efficiency, especially in complex scenarios (e.g., the Math task in experiments),” the researchers write.
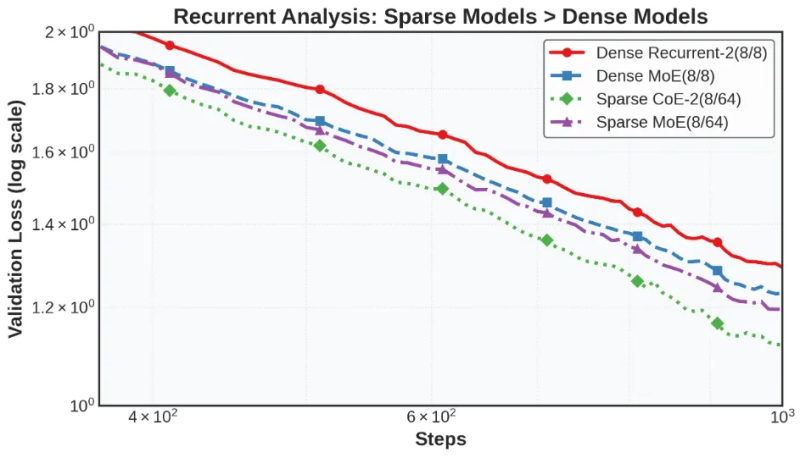
The researchers’ experiments show that with equal compute and memory budgets, CoE outperforms dense LLMs and MoEs. For example, in mathematical benchmarks, a CoE with 64 experts, four routed experts and two inference iterations (CoE-2(4/64)) outperforms an MoE with 64 experts and eight routed experts (MoE(8/64)).
The researchers also found that CoE reduces memory requirements. For example, a CoE with two of 48 routed experts and two iterations (CoE-2(4/48)) achieves performance similar to MoE(8/64) while using fewer total experts, reducing memory requirements by 17.6%.
CoE also allows for more efficient model architectures. For example, a CoE-2(8/64) with four layers of neural networks matches the performance of an MoE(8/64) with eight layers, but using 42% less memory.
“Perhaps most significantly, CoE seems to provide what we call a ‘free lunch’ acceleration,” the researchers write. “By restructuring how information flows through the model, we achieve better results with similar computational overhead compared to previous MoE methods.”
Case in point: A CoE-2(4/64) provides 823 more expert combinations in comparison to the MoE(8/64), enabling the model to learn more complex tasks without increasing the size of the model or its memory and compute requirements.
CoE’s lower operational costs and improved performance on complex tasks can make advanced AI more accessible to enterprises, helping them remain competitive without substantial infrastructure investments.
“This research opens new pathways for efficiently scaling language models, potentially making advanced artificial intelligence capabilities more accessible and sustainable,” the researchers write.

Source link